Il Semantic Web è finalmente una realtà!

di Luca Severini
Premessa
 La crisi economica che sta interessando l’Europa (e l’Italia in particolare) non favorisce gli investimenti nel settore IT. Il successo di compagnie come Apple, Samsung, Facebook, etc. mostra però che la domanda di tecnologia e delle sue applicazioni consumer è fortissima.
La crisi economica che sta interessando l’Europa (e l’Italia in particolare) non favorisce gli investimenti nel settore IT. Il successo di compagnie come Apple, Samsung, Facebook, etc. mostra però che la domanda di tecnologia e delle sue applicazioni consumer è fortissima.
Da questo si può dedurre che il mercato è influenzato prevalentemente dalla percezione che gli utilizzatori hanno rispetto al grado d’innovazione che l’offerta di tecnologia porta con se, piuttosto che da fattori prevalentemente economici o di necessità. In buona sostanza sembra che più l’offerta è tecnologicamente innovativa, più viene apprezzata.
Sotto questo punto di vista, il calo della domanda di prodotti e servizi IT da parte di imprese e della PA potrebbe non essere solamente dovuto alla crisi, ma anche dal fatto che le aspettative degli utilizzatori non coincidono con l’offerta disponibile. Come se il desiderio di novità non fosse soddisfatto dagli operatori impegnati a riproporre soluzioni tradizionali, con l’aggiunta d’innovazione poco significativa. Ad esempio, ERP offerti come SaaS in ambiente Cloud; App per funzioni già disponibili via browser; etc.
C’è comunque da tener conto che non sempre il grado d’innovazione viene percepito correttamente dagli utilizzatori. Conseguentemente, anche una forte innovazione potrebbe non decretare il successo di una tecnologia o di una sua applicazione.
Ciò dipende dal gap culturale che separa gli innovatori dagli utilizzatori. Spesso questo gap viene colmato in tempi brevi, altre volte possono passare anni dalla fase di proposizione sul mercato a quella di comprensione da parte degli utilizzatori della reale portata dell’innovazione tecnologica e dei vantaggi collegati al suo impiego.
Un caso emblematico è quello del Semantic Web.
Dalla sua teorizzazione ad opera di Tim Berners Lee avvenuta alla fine degli anni ‘990, sono trascorsi oltre 10 anni prima che si potesse colmare il gap culturale, ovvero che gli utilizzatori iniziassero a comprendere la vera differenza tra Web e Semantic Web.
Ciò è avvenuto a partire dalla metà del 2009 grazie a Wikimedia Foundation che, assieme all'Università di Lipsia, la Freie Universität Berlin e a OpenLink Software, ha dato vita alla prima concreta, significativa e utilizzabile applicazione degli standard del Semantic Web: Linked Data.
L’idea di fondo era quella di costruire il primo vocabolario per fornire una semantica condivisa ai data set pubblicati sul Web, partendo dal corpus di conoscenza fornito da Wikipedia. Si trattava cioè di dar vita a DBpedia - http://dbpedia.org/ .
Grazie a questa realizzazione, gli utilizzatori hanno potuto iniziare a pubblicare sul Web i propri dati, arricchiti da una semantica – finalmente – universalmente condivisa, e “toccare con mano” un’applicazione – comprensibile – del Semantic Web.
Così oggi si sta rapidamente diffondendo la conoscenza sulla “vera natura” del Semantic Web e la consapevolezza dei benefici che derivano dall’utilizzo delle tecnologie semantiche. Il gap culturale si va colmando e si apre finalmente la porta a questa incredibile innovazione tecnologica dalla portata epocale, le cui implicazioni sociali e culturali potranno essere paragonate a quelle conseguenti l’invenzione della scrittura.
Questo breve articolo vuole spiegare che cosa è successo, e che cosa verosimilmente accadrà.
Il valore semantico dell’aggettivo “semantico”
 Quello che Tim Berners Lee aveva in testa era chiaro. Bastava leggere qualche suo scritto per capire. Ma per comprendere era necessario già sapere di cosa si stava trattando. Scienziati e ricercatori che sin dagli anni ‘980 si occupavano di intelligenza artificiale sapevano bene cosa passasse per la testa al geniale inventore del Web. Tuttavia gli utilizzatori continuavano a non capire. Perché?
Quello che Tim Berners Lee aveva in testa era chiaro. Bastava leggere qualche suo scritto per capire. Ma per comprendere era necessario già sapere di cosa si stava trattando. Scienziati e ricercatori che sin dagli anni ‘980 si occupavano di intelligenza artificiale sapevano bene cosa passasse per la testa al geniale inventore del Web. Tuttavia gli utilizzatori continuavano a non capire. Perché?
Tim Berners Lee fece un grave errore lessicale: usò l’aggettivo “semantico” prima del sostantivo “Web”. Tutto qui.
Il Web già esisteva da oltre 10 anni. Oggi come allora il Web è una sterminata quantità di documenti digitali, pubblicati su Internet nei più disparati formati (html; doc; pdf; csv; txt; xml; etc.). Ogni documento è depositato su un server e possiede un suo indirizzo internet (URL). Grazie al protocollo HTTP il browser può raggiungerlo e visualizzarlo. L’utilizzatore può così leggerne il contenuto.
Ma cos’è il contenuto di un documento?
Il contenuto è un testo, arricchito da illustrazioni, immagini e audio-video, realizzato dall’autore del documento per trasmettere qualche sua conoscenza al lettore. Il documento contiene quindi la conoscenza dell’autore, informazioni e dati, formalizzata mediante il ricorso alla grammatica di un linguaggio naturale. Illustrazioni e altro materiale audiovisivo sono un compendio necessario a far comprendere meglio concetti e significati contenuti nel testo. Riferendoci al linguaggio naturale, e quindi alla dimensione dell’intelletto umano, il termine “semantica” assume il “valore semantico” tradizionale, cioè “significato dei segni” (o delle parole).
Poiché il Web già esisteva ed era appunto una enorme “biblioteca” di testi facilmente rintracciabili attraverso motori di ricerca lessicali, azionabili cioè attraverso delle parole chiave (keyword), l’aggettivo “semantico” non poteva che essere inteso nella sua accezione “umana” cioè riferito alle parole che compongono i documenti, ovvero al significato dei testi.
L’utilizzatore è stato così portato a pensare che il termine “semantico” si riferisse più alla proprietà dei motori di ricerca, piuttosto che alla qualità del Web, espressa appunto dall’aggettivo. Così, per molti anni, l’utilizzatore ha creduto che il Semantic Web fosse un particolare motore di ricerca capace di trattare il linguaggio naturale in modo ottimale. Un sedicente software capace di comprendere il significato dei testi, discriminare e associare tutti i documenti che “parlano” di certi argomenti, al fine di aiutare il lettore nelle ricerche sul Web. Cioè, un servizio del Web per limitare il “rumore” prodotto dai motori di ricerca!
Ovviamente Tim Berners Lee usa bene la grammatica e sa che gli aggettivi indicano delle qualità. Il Semantic Web è perciò diverso dal Web, è un’altra cosa. Il Semantic Web non è un servizio del Web, è un altro Web.
Ma cos’è questa qualità espressa dall’aggettivo “semantico”, e perché dovrebbe rendere il Web diverso da quello che conosciamo?
Tutti sanno che il computer agisce in modo mediato, eseguendo pedissequamente le istruzioni fornite dal programma. Il computer può eseguire le istruzioni grazie alla capacità di seguire la sintassi del linguaggio formale con cui è scritto il programma. Per questo motivo, i linguaggi formali e i metodi di programmazione sono considerate tecnologie sintattiche. Tutte le tecnologie utilizzate per far funzionare i computer sono sintattiche, comprese quelle impiegate dai motori di ricerca – le tradizionali tecnologie del Knowledge Management (information retrieval; text mining; data mining; data warehouse; NLP; etc.) – incluse quelle per realizzare le cosiddette “funzioni semantiche”.
Quando si scrive un programma che automatizza un determinato processo, il programmatore sa quali sono i dati in input, dove sono allocati, quali operazioni devono essere effettuate e quali dati devono essere presentati in output. Poiché il computer tratta la sintassi delle istruzioni, le tecnologie per la programmazione non sono adatte a rappresentare conoscenze aggiuntive (eg.: i motivi per cui l’operazione deve interessare certi dati piuttosto che altri; le caratteristiche per cui certi dati debbano essere impiegati in un dato contesto o no, etc.). Tutta questa conoscenza rimane nella mente del programmatore (o in qualche suo documento di testo) e non può essere così utilizzata dal computer per farne un uso più proficuo.
Sin dagli anni ‘970 gli scienziati che si occupavano di A.I. hanno però cercato di risolvere il problema della rappresentazione di questo tipo di conoscenza, affinché i computer potessero utilizzarla in modo automatico. Essi hanno studiato e creato classi di tecnologie adatte a questo scopo: le tecnologie semantiche!
In Computer Science quindi, con l’aggettivo “semantico” si indica quella particolare qualità delle tecnologie che possono essere impiegate per descrivere la conoscenza. Poiché i computer funzionano solamente grazie ai linguaggi formali (e non ai linguaggi naturali), quando comunicano non usano parole (come fanno gli umani) ma dati. Nel mondo dei computer quindi, il termine “semantica” possiede un “valore semantico” diverso da quello impiegato nel mondo degli umani: il termine “semantica” viene impiegato nell’accezione di “significato dei dati“!
Per deduzione, si può quindi facilmente intuire che il Semantic Web si differenzia dal Web poiché, pur utilizzando le stesse infrastrutture e gli stessi protocolli (http), in esso i dati pubblicati non sono dei semplici documenti, ma dei data set arricchiti da quella semantica necessaria affinché i dati possano essere utilizzati automaticamente dai computer. Un Web non pensato per gli umani ma per le macchine, incapaci di districarsi nell’astrattismo del linguaggio naturale ma fatte apposta per utilizzare rapidamente i costrutti grammaticali e logici di un linguaggio formale.
Quando Tim Berners Lee coniò il termine Semantic Web, egli pensava ai dati e alle tecnologie semantiche per trattarli in modo innovativo, e non ai documenti e alle tecnologie sintattiche già utilizzate per trattare il testo. E se a suo tempo avesse subito chiamato il Semantic Web in maniera diversa, ovvero avesse scelto due parole diverse da “web” e “semantico”, le cose forse sarebbero andate diversamente. Probabilmente il gap culturale si sarebbe potuto colmare prima poiché gli utilizzatori non sarebbero incappati in questo “bisticcio semantico”, proprio sul termine “semantica”!
Web dei documenti e Web dei dati
Nel 2009 DBpedia vede la luce e si concretizza una forma di Semantic Web chiamata – provvidenzialmente – Linked Data.
Grazie a queste due nuove parole, “linked” e “data”, impiegate per rappresentare il concetto di Semantic Web, gli utilizzatori iniziano a comprendere e, come accade nel mondo digitale, conoscenza e consapevolezza si diffondono piuttosto rapidamente.
Molte organizzazioni pubblicano i propri data set arricchiti semanticamente utilizzando tecnologie adatte a rappresentare la semantica (RDF; OWL; SKOS; etc.). Altre iniziano ad utilizzare queste tecnologie per pubblicare vocabolari che offrono la semantica relativa a specifici domini di conoscenza (eg.: GeoNames – http://geonames.org/ - un dizionario che rende possibile aggiungere la semantica per dati geospaziali; FOAF – http://xmlns.com/foaf/spec/ - un dizionario che rende possibile aggiungere la semantica per dati relativi alle persone; etc. etc. etc.)
Questa nuova situazione rinfranca anche Tim Berners Lee che vede finalmente concretizzarsi una delle sue idee più ambiziose. Sull’onda del successo, anche il W3C – il prestigioso consorzio da lui presieduto che si occupa degli standard del Web, http://w3.org/ , decide di rinnovare la pagina sugli standard del Semantic Web.
Abbandonando la descrizione ambigua che fino ad allora veniva offerta al lettore, la nuova pagina http://www.w3.org/standards/semanticweb/ sgombra ogni più flebile dubbio e svela la “vera natura” del Semantic Web: “In addition to the classic “Web of documents” W3C is helping to build a technology stack to support a “Web of data”, the sort of data you find in databases.”
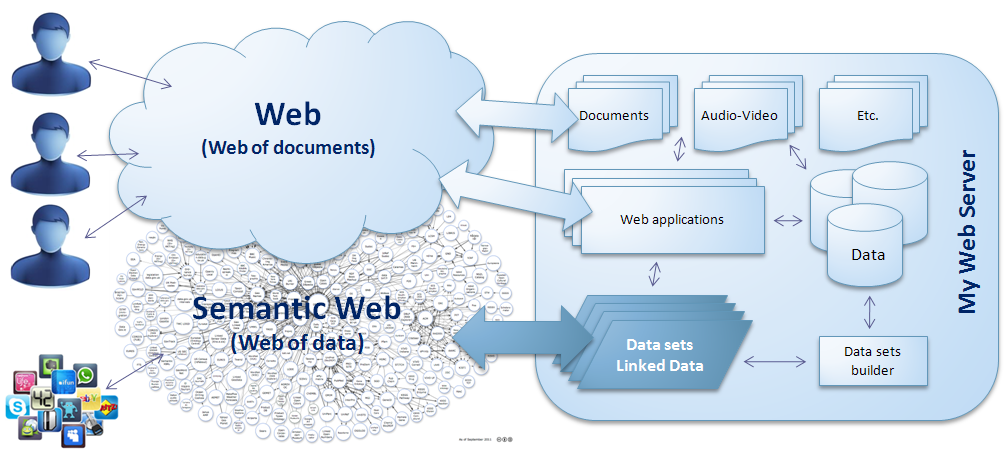
Quindi, un Web dei documenti (il Web), deposito di testi adatti a trasferire conoscenze umane ad altri umani, viene affiancato da un Web dei dati (il Semantic Web), luogo dei data set semanticamente arricchiti, adatti a trasferire conoscenze umane direttamente alle macchine.
Linked Data
Ma come accade per tutti gli organismi viventi, anche il Semantic Web è nato piccolo, immaturo. Adesso si sta manifestando in una forma semplificata che è appunto il Linked Data - http://www.w3.org/standards/semanticweb/data. Tuttavia questo semplice “organismo” ha già in sé “l’informazione genetica” che lo farà sviluppare e maturare nel tempo, facendolo diventare un unico, immenso, omnicomprensivo “World Wide Data Base”, cioè la quintessenza del Semantic Web!
Ma come funziona Linked Data?
Ogni organizzazione può essere considerata come un produttore di dati. Essi vengono generati da sistemi che automatizzano i processi informativi. Questi sistemi provvedono anche a collezionare i dati e a mantenerli in forma ordinata all’interno di apposite applicazioni software: i Data Base.
Se l’organizzazione desidera rendere disponibili alcuni di questi dati sul Web, le strade percorribili sono tradizionalmente due:
-
Esportare la porzione del Data Base da rendere disponibile, popolare con i dati esportati un file in un formato qualsiasi (html, pdf, csv, xml, etc.), e pubblicare il file sul Web;
-
Sviluppare un’applicazione software con interfaccia browser che accede, mostra e stampa le porzioni di Data Base da rendere disponibili, e pubblicare l’applicazione sul Web.
Questi due approcci hanno in comune il fatto che entrambi sono rivolti ad un utilizzatore “umano”. Infatti, è l’utilizzatore che deve usare le proprie conoscenze per comprendere il significato dei dati pubblicati, giacché esso non è esplicitato in modo formale, oppure è descritto mediante un linguaggio naturale che è comprensibile solo da un essere umano. Da questo ne consegue che se l’utilizzatore non è un esperto del dominio di conoscenza in cui quei dati assumono senso, ovvero non sa utilizzare l’applicazione software per consultarli, il significato dei dati non può essere mai colto.
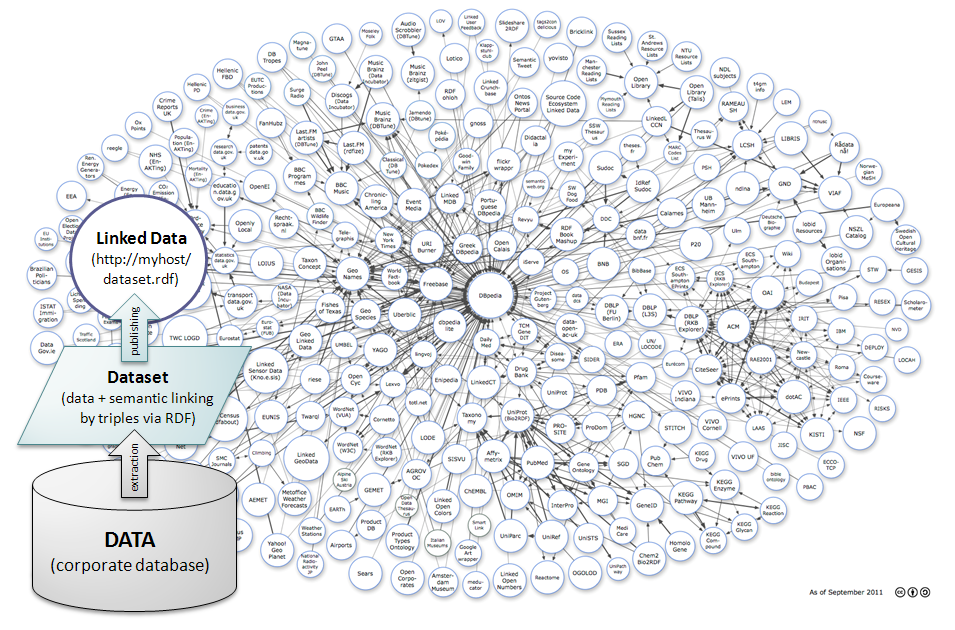
Ora però, a fianco di questi due modi tradizionali, esiste una terza possibilità:
-
Esportare la porzione del Data Base da rendere disponibile, popolare con i dati esportati un file in un formato conforme agli standard del Semantic Web, associare ai dati la semantica necessaria affinché i dati risultino linkati in modo pertinente ad altri data set correlati, inserire nel file i metadati che costituiscono la semantica, e pubblicare il file sul Web.
Con questa terza via, si entra nel paradigma del Semantic Web.
Ma come si fa a definire la semantica per creare un data set per Linked Data?
Supponiamo che l’organizzazione di prima voglia pubblicare la stessa porzione di Data Base come Linked Data. La fase di estrazione dei dati dal Data Base è la medesima. A questo punto però, la persona che conosce il significato di quei dati (essendo esperto della materia per cui quei dati hanno senso), deve effettuare una nuova operazione: il linking semantico.
L’operazione richiede la conoscenza del modo con cui si specificano le relazioni tra i dati ed ovviamente la grammatica RDF che lo consente. RDF (Resource Description Framework - http://www.w3.org/RDF/ ) è un linguaggio derivato da XML che introduce la possibilità di formalizzare la semantica attraverso le cosiddette “triple”, cioè un metodo per codificare una frase predicativa adatta a specificare una relazione. La tripla consiste in un formalismo che permette di esplicitare un soggetto, un verbo e un predicato verbale, a cui associare dei descrittori scelti opportunamente dai vocabolari già presenti su Linked Data. Se non fosse possibile recuperare descrittori pertinenti, si rende necessario aggiungere altri termini ai vocabolari esistenti o costruire ex-novo altri vocabolari e pubblicarli.
Ecco un semplice esempio di tripla:

Poiché questa conoscenza sui dati è frutto delle competenze di un essere umano, l’analista dati dovrà farsi carico di studiare i descrittori disponibili, scegliere i più adatti, progettare l’impianto della semantica più corretta per descrivere i dati, e inserirla correttamente all’interno del file RDF utilizzando uno dei tanti editor disponibili sul Web (eg.: Protégé – http://protege.stanford.edu/ ; etc.). Per essere sicuri di non aver sbagliato la sintassi, sono disponibili sul Web anche strumenti e servizi per validarla, come ad esempio il W3C RDF Validation Service - http://www.w3.org/RDF/Validator/ .
Questa operazione sostituisce sostanzialmente la tradizionale attività di associazione delle etichette ad una tabella (o della scrittura di semplici testi esplicativi da inserire nel documento contenente il data set). Ovviamente è un’operazione ben più complessa, ma nello stesso tempo il risultato è enormemente più potente. Infatti, espressa in questo modo, la semantica è ora disponibile anche per il trattamento automatico da parte dei computer.
Adesso il data set in formato RDF è pronto per essere pubblicato. Basterà copiarlo su un file system di un qualsiasi server esposto su Internet, affinché possa essere raggiunto attraverso una sua propria URL del tipo http://myhost.mydomain/mydataset.rdf , e il gioco è fatto.
Da questo momento, chiunque si avventurerà alla ricerca di dati relativi ad un determinato argomento, trovando il data set della nostra organizzazione di prima, non avrà più dubbi sulla pertinenza dei dati, poiché essi saranno linkati alle risorse universalmente utilizzate per descrivere quell’argomento.
Ecco il “perché” del Semantic Web!
Stato dell’arte
Linked Data è una forma embrionale del Semantic Web.
E’ talmente giovane che possiamo affermare di trovarci come si trovarono i più anziani tra noi all’inizio degli anni ‘990, quando era necessario caricare uno Slip sopra Windows 3.11 e attivare Mosaic il quale, a 9,6 Kbps (la velocità con cui si collegavano tramite linee telefoniche analogiche i Modem di allora ai terminal server dei primi provider commerciali di Internet), faticava non poco a scaricare le prime, rozze, scarne pagine Web.
Come allora per le pagine Web, anche adesso non esistono ancora dei motori di ricerca specifici per Linked Data: troppi problemi computazionali e infrastrutturali.
Ma, così come allora si affacciarono a poco a poco Altavista, Yahoo! e poi Google, in futuro avremo anche per Linked Data servizi di ricerca veramente utili.
Attualmente dobbiamo accontentarci di quello che offrono i motori di ricerca che indicizzano le pagine Web dei sistemi che mantengono gli indici dei data set (Linked Data Hub). Un esempio di Hub è quello del Governo del Regno Unito che pubblica Open Data anche in formato RDF - http://data.gov.uk/linked-data .
Un data set può essere descritto sommariamente in una pagina dell’Hub (eg.: http://data.gov.uk/dataset/staff-organograms-and-pay-hfea ), cosicché la descrizione possa essere regolarmente indicizzata dai motori di ricerca (eg.: http://bit.ly/REANbj ).
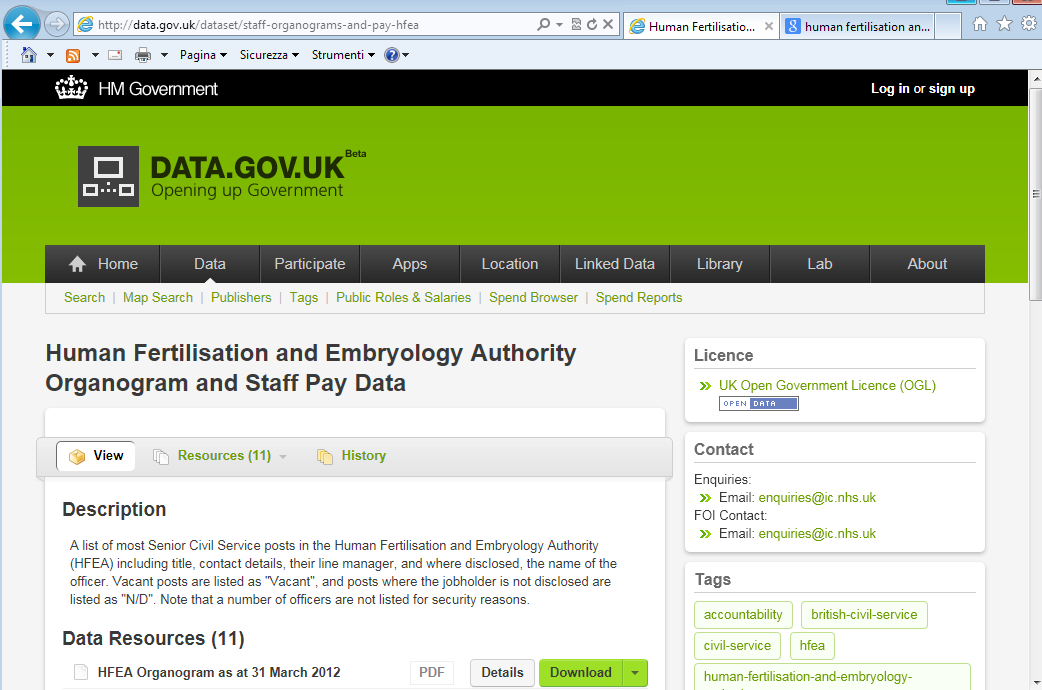
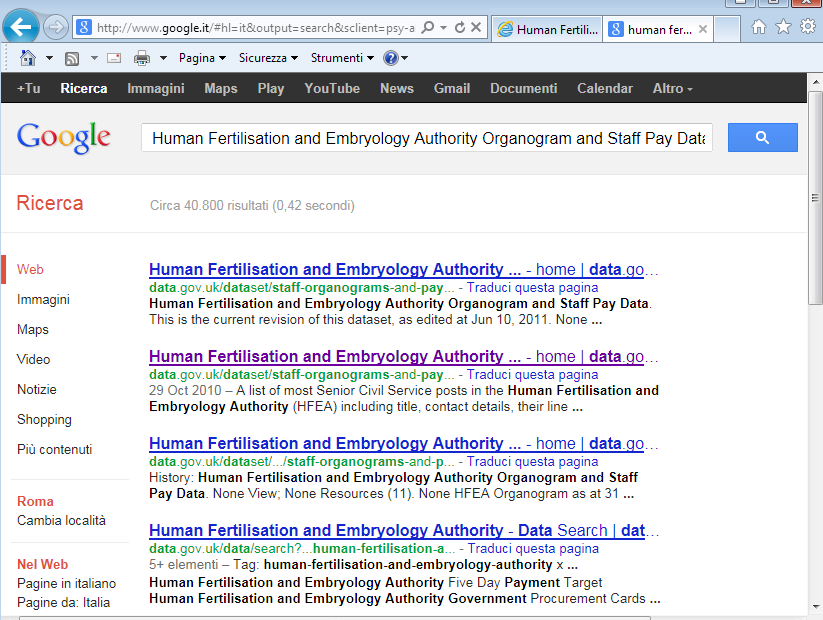
Ovviamente questo non è il massimo dell’aspirazione, poiché siamo ancora completamente all’interno dei paradigmi del Web! Tuttavia le cose cambieranno. E ragionevolmente a breve.
Alcune organizzazioni, quelle più vocate alla ricerca e all’innovazione, stanno sperimentando con ottimi risultati sistemi che adottano gli standard del Semantic Web.
Tuttavia i sistemi rimangono “isolati” (Corporate Semantic Web) e non possono considerarsi come veri e propri servizi per Linked Data. Comunque, almeno all’interno di un corpus di data set, questi sistemi offrono servizi interessanti e sicuramente utili per risolvere alcuni problemi non banali.
Una di queste organizzazioni è l’ESA – Europena Space Agency – che ha da tempo avviato un programma per rendere fruibili i propri data set spaziali sul Web (GMES Space Component Data Access - http://gmesdata.esa.int/web/gsc/home ).
L’ESA espone dei servizi sul Web per la ricerca dei prodotti spaziali (immagini della Terra) secondo un modello che permette di superare alcuni limiti oggettivi degli attuali sistemi di ricerca basati esclusivamente sul lessico. Questo per dare la possibilità ad utilizzatori non esperti di trovare i prodotti più adatti, anche senza averne prima conoscenza o coscienza.
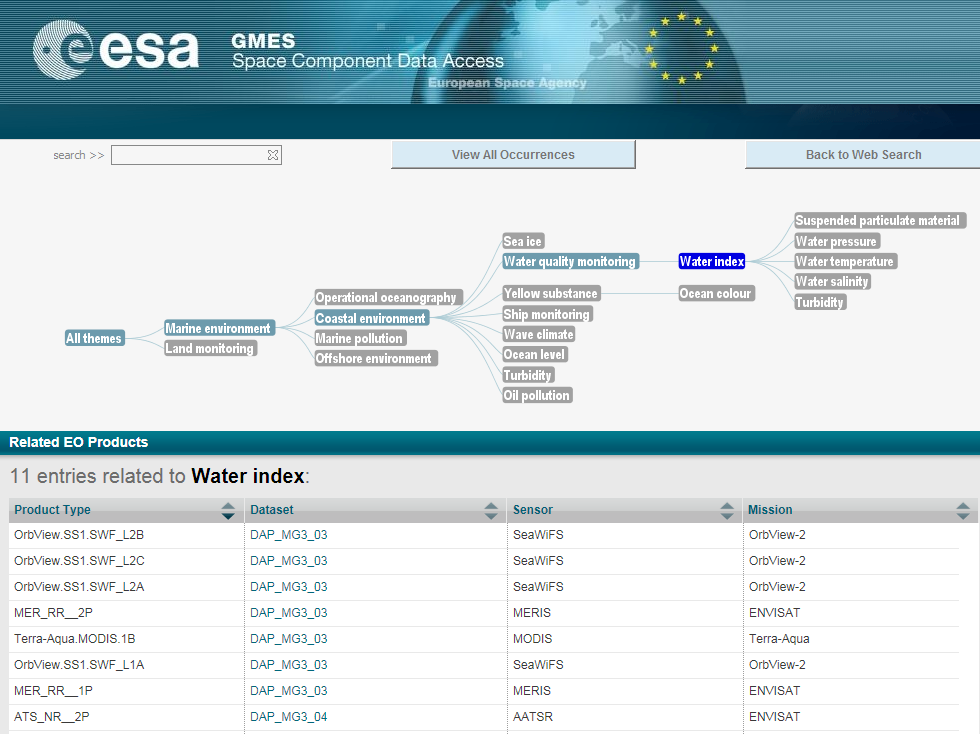
La soluzione adottata dall’ESA riduce questi problemi poiché i data set sono stati forniti della semantica necessaria per consentire all’applicazione di utilizzarla proficuamente. L’interfaccia uomo/macchina, in lingua inglese, usa la metafora del grafo. Selezionando le voci, il sistema lancia le query sui metadati e produce un risultato pertinente poiché utilizza le conoscenze degli analisti dell’ESA, i quali conoscono perfettamente il significato di quei dati. In pratica il sistema realizzato dall’ESA è un medium tra la conoscenza dell’utilizzatore e quella degli esperti di dati spaziali.
Per usare una metafora, il sistema di accesso ai dati implementa la funzione di un bibliotecario, capace di entrare in relazione con il lettore per offrirgli i testi più adatti a colmare le sue esigenze conoscitive. Ciò grazie al fatto che il bibliotecario è dotato di una sua conoscenza pregressa, relativa ai libri della sua biblioteca, che utilizza per offrire al lettore una potente funzione di ricerca “fisica”.
Utilizzando sistemi di ricerca tradizionali, invece, l’esperienza ci dimostra che se non siamo esperti di una certa materia non siamo nemmeno in grado di maneggiare il lessico utilizzato per rappresentare quel dominio di conoscenza. Quindi non potremmo mai individuare una keyword pertinente, utile a lanciare una query sensata. Di conseguenza, se non conosciamo già, non possiamo nemmeno cercare.
Inoltre, poiché il lessico dipende dalla lingua, non è facile effettuare ricerche su corpus documentali scritti in una lingua che non conosciamo. Conseguentemente, i documenti contenenti la conoscenza di cui abbiamo bisogno, scritti però in lingue che non conosciamo, saranno sempre e comunque ignorati.
Prospettive
In un futuro prossimo vedremo la nascita di servizi di ricerca, prima circoscritti a corpus di data set omogenei (come quello dell’ESA), poi sempre più allargati a tutto Linked Data.
Purtroppo però questi servizi richiedono pesanti elaborazioni e conseguentemente enormi risorse di calcolo. Infatti, un data set istanziato con una quantità ragionevole di dati, può trascinarsi un “carico semantico” enorme, a volte anche di ordini di grandezza superiore ai dati stessi: miliardi e miliardi di triple che devono poter essere elaborate in tempi ragionevoli al fine di realizzare applicazioni utilizzabili.
E’ facile intuire la “pesantezza” delle elaborazioni. Per risolvere questi problemi è necessario utilizzare computer molto più potenti che in passato.
L’approccio tradizionale host-centrico permette di immaginare soluzioni transitorie, e non certo a basso costo. Per fortuna però, il Cloud Computing sta aprendo scenari promettenti, inimmaginabili solo fino a pochi anni fa. La scalabilità offerta dalla virtualizzazione, abbinata alla possibilità di realizzare file system distribuiti su più host (DFS), attraverso l’impiego di middleware open source (eg.: Apache Hadoop - http://hadoop.apache.org/), permettono di progettare e realizzare infrastrutture altamente performanti e a costi contenuti.
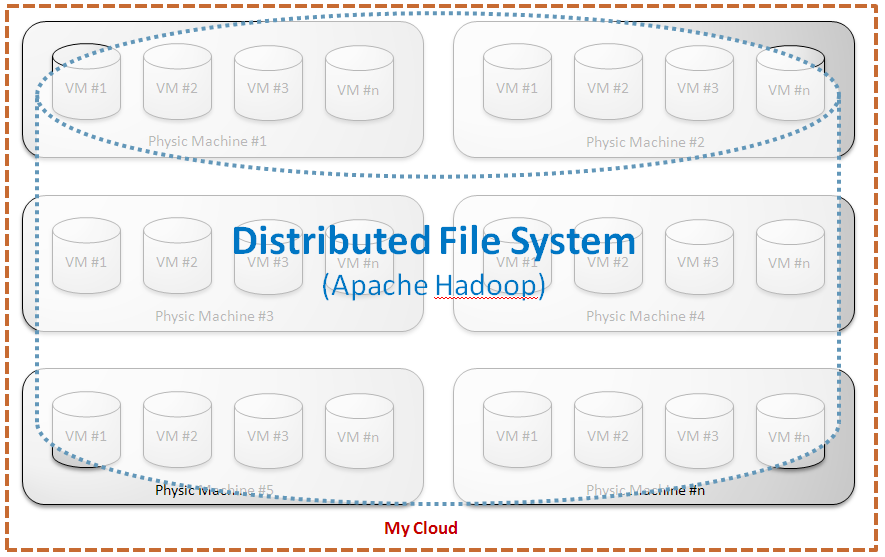
Si apre così la possibilità di usufruire della potenza offerta dal calcolo parallelo (Parallel Computing - http://en.wikipedia.org/wiki/Parallel_computing ) – tipico approccio utilizzato nell’ambito accademico e della Ricerca – per supportare lo sviluppo del Semantic Web.
Questa potenza di calcolo, teoricamente illimitata, potrà consentire di progettare applicazioni software innovative – in grado di sfruttare in modo ottimale la semantica – per creare servizi di nuova generazione, mai immaginati finora.
Per esempio, oggi sono disponibili tecnologie come OWL (Ontology Web Language - http://www.w3.org/standards/techs/owl#w3c_all) adatte a rappresentare la conoscenza mediante la Logica. A questo scopo vengono impiegate particolari porzioni della Logica: le DL (Description Logics - http://en.wikipedia.org/wiki/Description_logic).
Utilizzando questi metodi per rappresentare la conoscenza, risulta matematicamente possibile effettuare inferenza. Questa proprietà matematica ha dato la possibilità agli scienziati di sviluppare componenti software inferenziali (Semantic reasoners - http://en.wikipedia.org/wiki/Semantic_reasoner), cioè tecnologie semantiche adatte ad effettuare ragionamenti complessi (Automated Reasoning).
L’impiego di questa componentistica inferenziale per trattare i metadati che descrivono la semantica, assieme alla potenza di calcolo offerta dalle infrastrutture Cloud, apre la strada alla creazione di applicazioni software estremamente innovative e potenti. Molto potenti, poiché ormai capaci di “ragionare”.
L’evoluzione del Semantic Web avverrà inesorabilmente verso questa direzione.
L’evoluzione sarà poi sostenuta da ulteriori innovazioni tecnologiche che sono ormai alla porta, tra cui la creazione di nuove iper performanti Reti in fibra ottica che permetteranno di scambiare una quantità di dati enormemente più grande di adesso; e da innovazioni epocali come l’introduzione sul mercato dei Computer quantistici - http://it.wikipedia.org/wiki/Computer_quantistico, capaci di elaborare quantità di dati pazzesche; ma soprattutto dalla capacità delle macchine di utilizzare autonomamente la Logica, unico linguaggio simbolico universalmente condiviso da ogni essere umano, di qualsiasi razza, cultura e grado d’istruzione.
Conclusioni
L’impiego delle nuove tecnologie semantiche e la disponibilità di infrastrutture altamente performanti, permetteranno al giovane Semantic Web di crescere ed affermarsi, aprendo un nuovo scenario in cui le macchine saranno veramente al servizio dell’umanità, così come oggi un bravo bibliotecario è al servizio del lettore.
Grazie allo sviluppo del Semantic Web si potrà manifestare così la futura Società della conoscenza, quella forma di società in cui la conoscenza umana si trasferirà da uomo a uomo secondo nuovi paradigmi, diversi da quelli dell’attuale Società dell’informazione che sono basati ancora sugli stessi modelli che l’umanità usa sin dai tempi dell’invenzione della stampa a caratteri mobili. Un modello che adesso mostra i suoi limiti proprio a causa dall’uso intensivo delle tecnologie dell’informazione e della comunicazione (ICT).
Infatti, la disponibilità illimitata di contenuti sul Web, unita alla semplicità di reperirli, sta determinando un overload informativo a cui il genere umano è sottoposto per la prima volta nella sua storia. Poiché il paradigma con cui si trasferisce la conoscenza da uomo a uomo è basato ancora sulla scrittura e la lettura, di fronte alla mole di documenti disponibili, l’uomo spreca la maggior parte del proprio tempo a discriminare l’informazione utile da quella inutile. Ciò determina che il tempo per apprendere, ovvero per la fase di trasferimento della conoscenza mancante, si assottigli sempre più.
Ma nella nuova Società della Conoscenza i computer si comporteranno come medium tra la conoscenza dei saggi (autori) e la nostra (utilizzatori), e non più solamente come desolati depositi di documenti dematerializzati, così come avviene oggi.
La Società della conoscenza perciò, non è quella forma di società in cui la conoscenza umana è disponibile poiché i documenti che la contengono sono pubblicati sul Web – così come comunemente ci fanno intendere! Ma sarà quella forma di società in cui la conoscenza umana, codificata in forma “decidibile”, sarà trattata automaticamente dalle macchine che ci restituiranno direttamente solo quei pezzi di conoscenza a noi mancante.
L’uomo non sarà più costretto a spendere il proprio tempo e le proprie energie intellettuali per discriminare sulla base di quel poco che già sa, ma grazie alle macchine, potrà finalmente dedicarsi interamente all’apprendimento, per colmare le proprie lacune del sapere.
Luca Severini, è la persona che ha coniato il termine “epistematica”. Nel dizionario italiano esiste il termine “epistematico” [deduttivo] impiegato come aggettivo maschile. Il sostantivo femminile “epistematica” è una nuova voce composta dai termini "epistème" [conoscenza] e "informatica" [trattamento automatico dell'informazione], che assume per analogia il significato di "trattamento automatico della conoscenza". L'Epistematica studia, crea e applica tecnologie che permettono ai calcolatori elettronici di simulare comportamenti intelligenti mediante processi inferenziali effettuati su apposite basi dati arricchite semanticamente, dette basi di conoscenza. Vedi anche http://it.wikipedia.org/wiki/Epistematico
Luca Severini è il fondatore della società che prende come denominazione il termine da lui coniato. Epistematica Srl è l’impresa che per prima in Italia si è specializzata nell’applicazione delle tecnologie semantiche per la formalizzazione e il trattamento automatico di conoscenze. luca[at]severini.org